
We at Cedar believe that one of the most frustrating issues being faced by hundreds of millions of people in the US can and should be better: making sense of their healthcare bills. We are applying large language models (LLMs) to help patients in their healthcare journey. Using LLMs, we can create a scalable solution that helps all types of people in a variety of situations navigate the complexities of the healthcare system, with empathy and compassion.
While Cedar's billing solutions aim to enhance the overall patient financial experience, there are instances where individuals require additional clarification regarding their bills. Patients often engage with service centers or representatives through phone calls and chats, incurring significant time and cost burdens for both patients and healthcare providers.
Consider a patient - let’s call him Alan. He received a text message notifying him that he now owes a few hundred dollars of bills from a series of hospital stays. He was surprised by the bill - he was under the impression that he had already paid for the care. He doesn’t fully understand his bill and is not sure what his next steps should be. He opens the Cedar app hoping to talk to somebody, navigates to the “Contact Us” page, and is now connected with our service center representative, Turing.
What type of information does Turing need to guide Alan through his bill? Turing would first need up-to-date information on Alan’s invoice, and might identify that although Alan had paid for the surgeons who operated on him, the bill he received is for the anesthesiologist. He also needs to check Alan’s insurance - maybe Alan’s insurance was not even applied and Turing needs to resubmit the claim, or maybe the insurance has already covered the bill and the remaining amount was just the copay. If it is the latter case, Turing can direct Alan to submit a financial aid application, and make sure Alan follows the most up-to-date application process so that Alan can fully take advantage of what the hospital has to offer.
Turing's expertise in patient services positions him effectively to guide Alan through the intricate landscape of healthcare billing, marked by complexities like:
- Multiple entities involved in billing. A typical hospital visit in the United States may have multiple healthcare providers taking care of a patient, each of whom bill that patient separately, and have a different interaction with the patient’s insurer.
- Variation in policies and individual patient circumstances. The wide variety of insurance policies and individual patient situations make it difficult to find solutions that are “one-size-fits-all.”
- Regulatory compliance. Adherence to numerous healthcare regulations, including those that ensure security and privacy of patient information.
In this blog post, we delve into the development of an architecture that facilitates personalized responses to patient queries, streamlining the process and alleviating stress.
We can use LLMs as a tool when solving problems in healthcare billing. The adaptability of LLMs allows them to adjust to various data sources and problem domains, including the types that are observed in healthcare billing use cases. LLMs can comprehend the semantic meaning behind language, understanding not only complex medical terminology, billing codes, and regulatory language, but also the language used by patients who are reaching out with questions. LLMs can thus be a valuable link between the complicated world of healthcare billing and patients who are looking for easily understandable explanations that meet their needs.
We knew that LLMs would be useful - but they don't fulfill this promise out of the box without a lot of elbow grease and research. In 2023, we worked on solving several challenges we faced while building a chat assistant. In this article, we'll document our experiments and what we've learned - sharing those challenges, and exchanging ideas and solutions, to collectively enhance our capabilities and ultimately lead to better patient experiences.
Challenge 1 - So much data, so little time
Back when we were data scientists-in-training, our first encounter with machine learning involved a dataset that was already clean and well-structured, and our job was to train the model to produce the best outcome for this dataset. Sometimes our TAs sprinkled in a few intentional complexities, to bring it closer to the “real world.” But working with LLMs in true real-world applications, the paradigm is flipped - the models themselves are usually already state-of-the-art. It is the content and the quality of the data in the input prompts that primarily control the model’s output, making data curation a critical task.
The age-old golden rule of “garbage in, garbage out” stands especially true for LLMs. Our dataset is how we impart information the general purpose models do not have. This healthcare billing data that is needed could be anything from hospital financial aid policies to outstanding amounts on a particular patient’s bill. To conduct development, testing and evaluation, we need to systematically produce the best dataset that:
- Protects patient privacy by removing all Protected Health Information (PHI) that may be used to identify an individual, such as patient names and medical record numbers– we would never want one patient’s private data to show up in a response to another patient’s questions.
- Captures how we would like the model to behave in a wide range of scenarios and language styles– we want to present an empathetic, professional tone.
- Serves as a reliable and up-to-date source of healthcare provider specific information– we need to provide personalized answers in a world of changing regulations, policies and patient scenarios.
We embarked on an initial round of data cleaning with two data scientists and a large spreadsheet, hoping to learn on the go, and adjust efficiently as we experiment. Not surprisingly, the first thing we learned is that curating a dataset is costly and hard. Cleaning and tagging the dataset requires a clear and consistent set of labeling guidelines; as new issues and edge cases are discovered in tagging, the guidelines can drift, requiring those working on annotating the dataset to sync and update their discoveries in a timely manner. We also learned that consulting subject matter experts (in this case, our service center representatives– known by Cedar as “Patient Advocates”) is an indispensable step - having them reviewing our tagged data and our assumptions led to much more accurate and contextually relevant data.
Although a valuable learning process, in-house manual tagging is not easily scalable. Fortunately, state-of-the-art LLMs are known to have an ability to perform well in data tagging tasks when provided sufficient guidance and demonstrations. We used the manually-tagged data as few-shot examples, which are a small set of carefully selected instances used to guide the LLM in understanding and executing specific tasks. This data was then used to prompt the LLMs to behave as an “unstructured data pipeline” using a chain-of-thought approach:
- Step 1 - Data Cleaning
- “Remove all lines that ONLY contain greetings, sign-offs, repetitive or redundant lines, and lines that do not contain information related to the issue or its resolution…”
- Step 2 - Segment Understanding
- “Consider and describe how many segments that exist in this transcript, with each segment being a separate theme discussed …”
- Step 3 - Segment Parsing
- “Identify the initial query of the patient, and label it as 'Patient Query'..”
- Step 4 - Labeling
- “Classify the input into one of the following categories, using the following instructions:..”

In our experiment, LLMs demonstrated amazing ability to parse, transform and label the data. Note that the goal of the parser is not to replace manual review, but to significantly reduce noise and transform unstructured data to forms that are easy to review, analyze, and later ingest.
Challenge 2 - Fact, not fiction: reducing model hallucination
LLMs hallucinate when they are not sure. A general-purpose LLM may not know how a particular provider splits the bill between the physician and the nurse, or which charities the hospital is currently working with at this moment to provide financial aid. When prompting out-of-the-box LLMs with those questions, it will refuse to answer, or provide an unreliable result. To achieve personalization, the model needs to know patient bill details, and cannot risk leaking one patient’s data to another; it will also need to have the most up-to-date hospital and insurance policies, and have the ability to refresh this knowledge when the policy changes. Our task is to effectively embed this rich context into the model, reducing the model’s uncertainty while maintaining tight control on the output.
Imagine a college student taking a challenging exam. Coming up with all of the answers from memory can be difficult, but trying to flip through an entire textbook for answers is not the best strategy either. Our objective is to develop an ideal reference guide for the student, offering a succinct yet comprehensive resource that provides accurate information, filled with salient data points that the student can trust to pull answers from. This is why we are taking a Retrieval Augmented Generation (RAG) approach, allowing us to effectively update the model’s internal knowledge. RAG combines language modeling with real-time data retrieval, prompting the model with information dynamically retrieved from external databases, allowing for an easy way to enrich responses with real time patient- and provider-specific information.
Our LLM – our student, in the previous analogy – receives questions from the patient about their bill (e.g. “Why is my bill so expensive? I thought my insurance covered this.”). As the LLM receives each patient question, the LLM will also get a curated high-level summary – the “reference guide” from our earlier exam – of key information:
- Overall task instruction. Explaining to the bot that they will be attempting to respond to this patient billing inquiry, and should “take a deep breath and do it step by step”.
“You are an empathetic professional chat assistant who responds to patient billing questions; when you are not sure, respond ‘Sorry, I can’t help with that’...”
- Category + resolution instructions for that Category. In a healthcare environment with many regulations and policies, there are going to be defined approaches for how to resolve a certain type of patient inquiry. We have developed a method to categorize a patient’s question, and have built a database that describes, for each category, what steps need to occur to resolve the inquiry. These pre-written “resolution instructions” describe how exactly to utilize a patient’s account details to answer a question, guiding the LLM in a step-by-step format.
“First, empathetically tell the patient that you understand they are looking for assistance with their bill. Then, using the context information given…”
- Patient bio, which is patient-specific information (e.g. bill and account details) pulled from our database. This is the key to a truly personalized response that guides a patient through their own individual situation.
“Invoice 1 is from a visit to X Hospital on 2022-11-08. The treatment is Anesthesia (Lower Abdomen)... “
- Few-shot examples, examples from our reviewed golden dataset of similar patient queries and how they were answered.
“Q: Why did my insurance not cover this? A: It looks like your primary insurance has already covered it, and the remaining amount is out of pocket.”
Using this multi-faceted approach, we nearly eliminated the model’s tendency to hallucinate, and enabled the LLM to produce accurate, personalized responses to patient questions. During development and testing, we closely collaborated with Patient Advocates who work at the servicing center resolving patient billing queries via chat and phone calls. During a manual scoring exercise, the Patient Advocates gave high ratings to the LLM-generated responses in categories such as Helpfulness, Empathy, and Professionalism. Collecting feedback on AI-generated responses will continue to be an area of emphasis throughout the lifecycle of this product, and will influence the design of the tool that we bring to production: our Patient Advocate AI Assistant.
Challenge 3 - Building for the human in the loop
Our goal is to create a “Patient Advocate AI Assistant” that will strive to be the best possible copilot to the Patient Advocates who are conducting chats with patients. The Patient Advocates themselves serve as an additional guardrail against inaccuracies and hallucinations in the LLM-generated responses, ensuring that any content seen by a patient is relevant and appropriate.
With their insight and experience in resolving patient billing inquiries, the Patient Advocates act as our “experts-in-the-loop.” If we can collect feedback on LLM-generated responses from the Patient Advocates, who have expertise in handling incoming questions from patients, this feedback will enable us to improve our solution over time.
We are designing our tool in such a way that the Patient Advocate can review the LLM-generated output and do any one of the following as a next step:
- Send the suggested output as-is (“Send now”)
- Edit the output and send an edited version (“Copy and edit”)
- Choose to not use the suggested output, and compose a response from scratch (Enter a message)
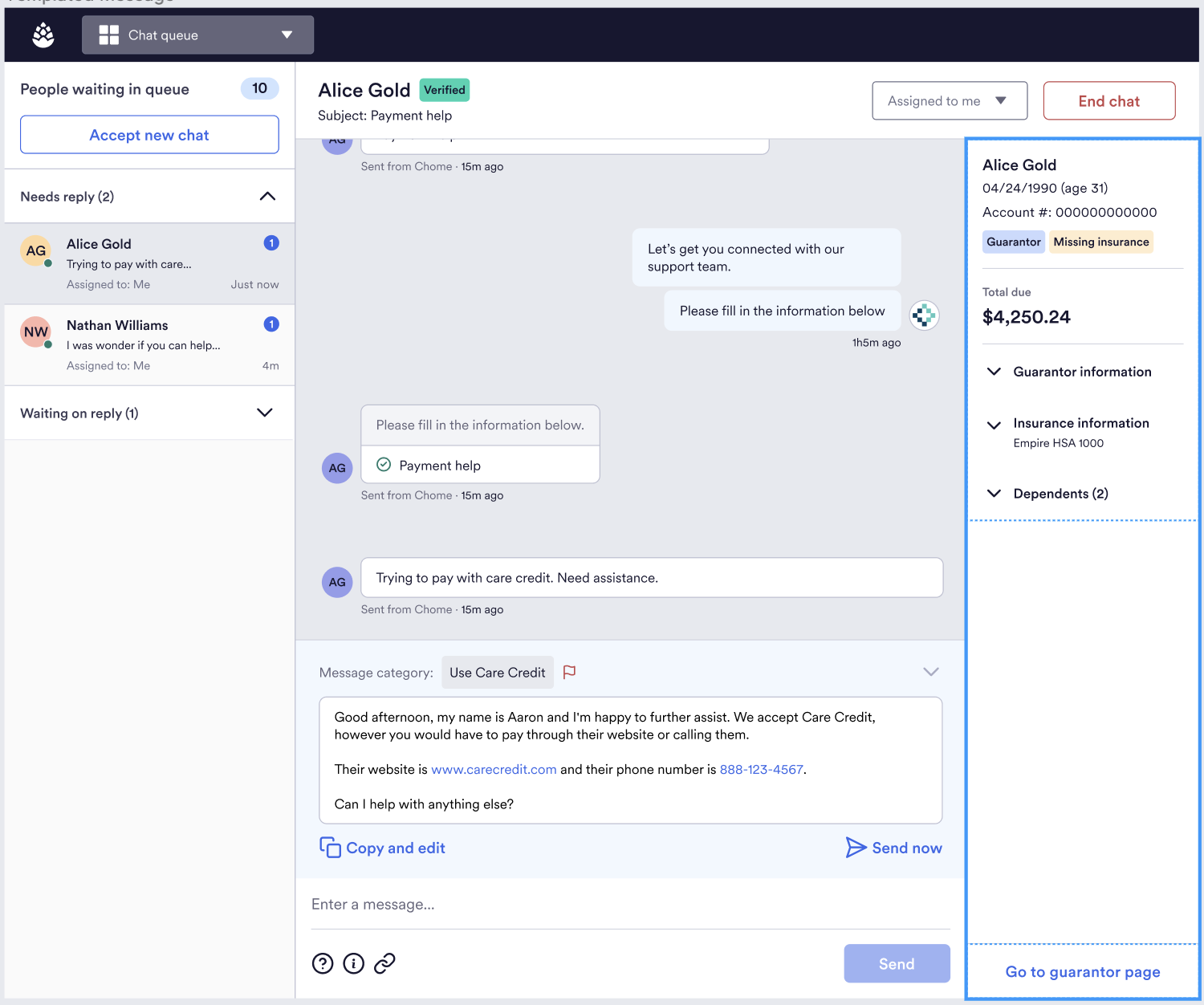
By logging the action taken by the Patient Advocate, we will track which responses were high quality (i.e. sent without editing), which were on the right track but needed some adjustments (i.e. sent with editing), and which were not helpful at all. This is extremely valuable information that will be one of the driving forces behind improvements to our application (building towards Reinforcement Learning from Human Feedback or RLHF). Eventually, we may be able to surface responses directly to the patient in a fully-automated way (for the more simple questions), enabling Patient Advocates to focus on the more complex cases that require the attention of a human expert.
Challenge 4 - Protecting Patient Data
LLMs can make a big impact on how a patient navigates their healthcare journey – but invoking LLMs and deploying LLM-powered applications safely creates unique challenges, because LLM applications can introduce new ways to expose patient data that break traditional threat models. Malicious actors may try to target the system to extract patient information or interrupt functions. We focused on building an understanding of LLM-specific attacks that target patient data at the application layer using the latest research in the application security space by industry leaders like OWASP, Cloud Security Alliance, and the Berryville Institute of Machine Learning. In tandem, we designed a secure multi-cloud infrastructure to protect patient data throughout the LLM application lifecycle and prevent unauthorized human access to the data.
Since real patient interactions are used to build the chatbot, it’s imperative to protect patient data during the development phase by redacting protected health information (PHI) and other sensitive data. When preparing chat data for analysis, we run AWS Comprehend within our data pipelines to redact PHI from chat interactions. Scrubbing the dataset using this service eliminates the possibility of leaking sensitive data, protecting the privacy of our patients while enabling secure and rapid development of the chatbot.
In production, whenever our application makes an invocation to the LLM, we protect against dangerous attacks like prompt injection, request forgery, and output manipulation, which pose serious threats to data confidentiality. Imagine if the chat assistant were to mistakenly reveal insurance details of one patient (e.g. Bob) to another (e.g. Alan), when Alan only wanted to update his own insurance details! To prevent this, we securely retrieve only the necessary PHI of an authorized patient by leveraging Cedar’s in-house encryption/decryption service. By categorizing the patient’s inquiry (e.g. “update insurance on file” for Alan’s case) and having category-specific data retrieval workflows to retrieve the relevant account details, we define a clear boundary of information that is needed to resolve the patient’s request.
It’s not enough to defend against attacks at the application layer. Attackers will always look for the weakest entry point to a system, so it’s critical that the LLM also runs on secure infrastructure. Cedar’s underlying infrastructure is powered by AWS (Amazon Web Services). But as part of this project, our infrastructure evolved into a multi-cloud environment with GCP (Google Cloud Platform) and relies on end-to-end network protections, a well-defined access control model, and limited human access to patient data.
Navigating the complexities of a multi-cloud environment involves introducing a new network connection between GCP and our existing AWS services. We’ve strengthened our data security and segregation by isolating connections to the Google AI environment using secure TLS API calls. We’ve taken care to create well-documented log streams to detect malicious activity and restrict access from GCP to our AWS cloud infrastructure following the principle of least privilege. According to OWASP's Project Top 10, the most common point of entry to a private network came from broken access control measures. To protect patient data from compromised users, we’ve established IAM’s fine-grained access control to restrict access to resources in the chat service. By using a dedicated set of IAM roles when interacting with AI services in GCP, we draw a well-defined boundary between our cloud environments and limit the blast radius of a potential attack. For instance, when a patient sends a chat message asking to update their mailing address, our secure network and strict access control not only ensure safe retrieval and storage of both the current and new addresses but also protect against external security risks such as unauthorized access or data breaches, ensuring our patients’ privacy and trust.
Conquering challenges and navigating a new landscape
With any new technology comes challenges, and this is true for LLMs. We have learned so much over the past few months, and are excited to learn even more. The Patient Advocate AI Assistant is just one of several LLM use cases we are developing– throughout the Cedar product suite, there are many opportunities for us to positively impact the healthcare financial experience at key touch points throughout the patient journey. Alan might feel that his bill is as complex as an Enigma machine, but we think we can help him crack the code. Cedar has a history of successful ML applications and we are excited to add LLMs to our toolkit as we build products that will serve our mission to make healthcare more accessible to patients!
We would like to thank Max Chen, Aaron Zollman and Kinshuk Mishra for their contributions to this blog post.
To learn more about Cedar, visit our website here.
Interested in a career at Cedar? Check out our careers page.

