Cedar works with healthcare providers (such as hospital systems and clinics) to deliver a great financial experience for their patients. To do this, Cedar needs to build robust data integrations with our providers.
While every data integration that we build accomplishes the same set of goals, no two provider integrations are identical. Data exchange methods, data format (both incoming to Cedar and incoming to the provider), transfer frequency, and other aspects vary widely across each integration.
Building and maintaining end to end automated tests for many complex, disparate integrations is challenging. We originally built end-to-end tests for each integration independently, but this approach led to limited test coverage and limited reuse of test code across integrations.
Based on our learnings, we built a new automated test framework based around scenarios. Scenarios represent key product workflows that involve integrations. They make use of a standard api to seed provider source data, which allows the scenarios to abstract away complexity around each integration’s data format, exchange method, and transfer frequency. Scenarios can be built once, and re-used across tests for most or all integrations. With this approach, we’ve been able to achieve much greater test coverage, improved test readability, and improved test maintainability, all with minimal to no increase in time to build the tests.
In this post, we’ll first provide more context on why we integrate, and explore why provider integrations look different from each other. Then, we’ll deep dive into how our integrations work, and demonstrate with examples how we’ve evolved our automated test framework.
Why we need to integrate
Cedar enables patients to do things like:
- Check-in for an upcoming visit. Patients can see detailed estimates of what their visit will cost, update their contact or insurance information, and pay their copay in advance.
- View and pay their bills after their visit. We provide patients with rich detail to help them understand why their bills. We provide flexible payment options, and give patients tools and insight to help them resolve problems with their bills.
In order to support these workflows, Cedar needs to pull a detailed set of data into our database from the databases used by our providers. Our providers use electronic medical record systems (EMRs) to track all their important clinical and billing data.
- Example data sets that we pull from the EMR into Cedar: Patients, Insurance policies, Appointments, Cost Estimates, Bills, Insurance Coverage, pre-existing Payments
In addition, we need to ensure that any updates from Cedar’s patient workflow are reflected in the EMR, so providers have an up-to-date picture of what’s happening with their patients.
- Example data sets that we push from Cedar into the EMR: Appointment Check-In Status, Patient Payments, Payment Plans, Updated Insurance, Updated Contact info
It’s important to note that all of the above are incremental syncs. When we pull from the EMR, we need to receive all relevant data points that are new or changed since the last pull. Similarly, when we push to the EMR, we need to push all relevant data points that are new or changed since our last push.
Why provider integrations are different from each other
There are about a dozen EMRs used by most large healthcare providers in the US, and Cedar’s providers use most of them.
EMRs have vastly different capabilities when it comes to data exchange.
- Some have robust APIs, although typically not for the entire scope of data we require.
- In addition, most EMR APIs can retrieve data for a single patient, but they can’t provide updates on new or changed patients over time, so they’re of limited value for our use case.
- Most EMRs have support for standard methods of data exchange, like HL7 or FHIR, but again, data scope is limited.
- In many cases, we need to resort to asking the provider to produce custom flat files to extract data for us, and receive custom flat files in return that they ingest into their EMR.
- In some cases, flat files aren’t even a viable option, so Cedar interacts directly with the EMR database.
Even for a specific EMR, different versions of the EMR may present very different data and methods for interacting with it. In addition, providers can typically customize a significant amount of the data schema in their EMR to fit their workflows.
Next up, let’s dive deeper into how our integrations work, and how we test them.
Going deeper on integrations
In our integrations framework, we have two key concepts: ETLs (Extract-Transform-Load) and Syncs.
An ETL is a data task for a specific data set.
- For example, we might run a pull ETL to extract patient data from an EMR, transform it, and load it into the Cedar database.
- Similarly, we might run a push ETL to extract recent patient payments from Cedar’s database, transform them into a format the provider’s EMR can accept, and write it to a flat file on an SFTP server.
A sync is a logical grouping of ETLs that run in sequence on a specified schedule.
- For example, we’ll typically run a pull sync for a provider whenever new data is available from the EMR, be it daily, hourly, or near-real-time. A pull sync would include ETLs such as a patient pull ETL, a patient insurance policies pull ETL, and many more.
- Similarly, we’ll run a push sync as frequently as the provider’s EMR can accept new data. A push sync would include ETLs such as a payments push ETL, a payment plan push ETL, and more.
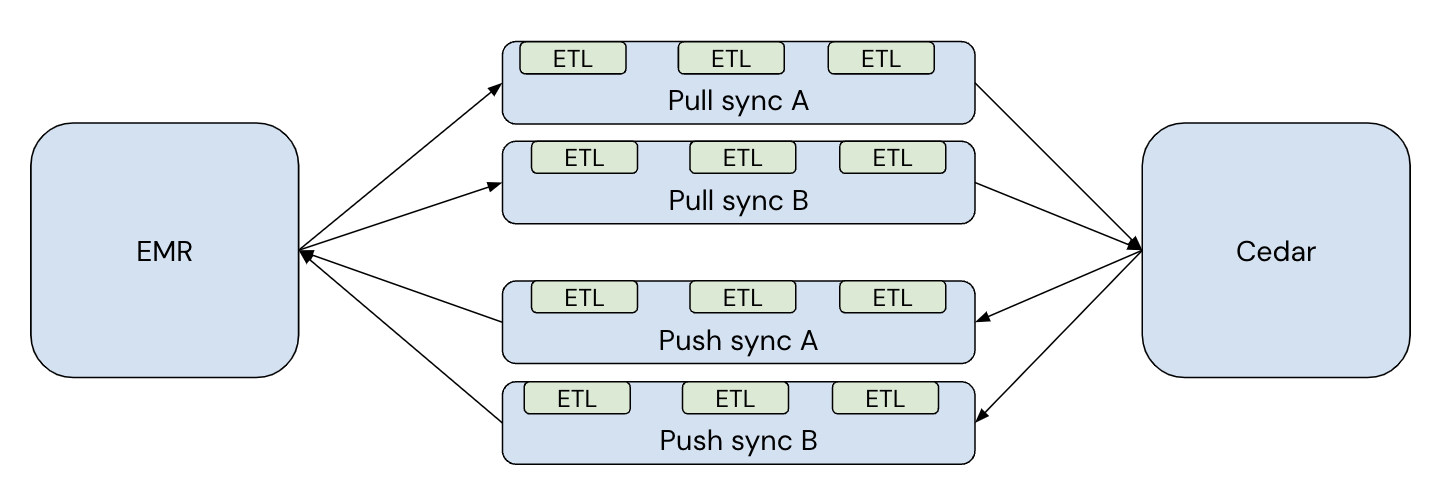
We write unit tests for each ETL. In addition, since ETLs can read from and write to the same tables in the Cedar database, ETLs can impact each other, both within and across syncs.
- For example, the pull ETL that loads patient insurance policies into Cedar depends on the pull ETL that loads patients into Cedar, since the former needs to associate insurance policies with the correct patient in the Cedar database.
- Similarly, the push ETL that pushes patient payments back to the EMR also depends on the patients pull ETL, as it needs to include the correct patient identifiers on the payment record that we send to the provider.
These data dependencies can be quite extensive and complex, so we need integration tests for our integrations!
Integration integration tests v1
In v1, we build integration tests one sync at a time. We do this by:
- Manually curating a data set for the sync. This is mock EMR data for a pull sync, or mock Cedar data for a push sync.
- Running the mock data through the sync, then manually writing assertions for the output. This includes checking the contents of the Cedar database, and checking the data we would push back to the provider.
In the following example, Cedar receives data from the EMR about a patient and an upcoming appointment, runs a pull sync to load that data into our database, and verifies the data was loaded correctly.

Pros of this approach:
- Enables us to ensure that all the ETLs in a sync function correctly together
- This a black box test, so changes to how the sync works under the hood don’t require changes to the test
Cons of this approach:
- Manual curation of the data takes time, particularly when testing a pull sync.
- It’s not easy to understand what’s happening in the test, particularly with a larger set of EMR data
- The engineer writing the test needs to remember all the most important cases to cover in the data, and the right things to check in the output
- While it is possible to run multiple syncs in a single test, the test case would become even more complex and harder to maintain.
Integration integration tests v2
We built a new integration testing framework that we call the “sync scenario test framework”. Like v1, it is a black box test framework, but includes some key enhancements.
At its core, the sync scenario test framework is built around scenarios. A scenario:
- Represents a key product workflow involving one or more syncs
- Can execute any number of pull or push syncs throughout the scenario
- Uses a standard interface (called the seed manager) to seed mock EMR data
- Runs a standard set of assertions
- Is expected to be re-used across most/all providers/EMRs
Following a similar use case to the above, here is an example scenario:

How this works behind the scenes:
- Rather than construct files for a specific provider/EMR directly, the scenario uses a seed manager with a standard interface to seed EMR source data.
- The seed manager then generates input files for the pull sync using a fixture generator.
- The fixture generator is specific to each EMR/provider. It is a class that maps from the seed manager data model to the EMR/provider data model used by the pull sync.
Pros of v2 vs v1:
- The scenario is reusable, so we only need to define it once!
- An engineer testing a new integration can use all of the existing scenarios we have built, without needing to remember them.
- As compared to a v1 test, the scenario is much easier to read, as we have no EMR-specific file formats involved
- The simpler structure of the scenario allows us to more easily model complex workflows, such as pull syncs, followed by patient actions, followed by push syncs, followed by more pull and push syncs. We can even compose scenarios to model more complex workflows, while keeping the scenarios themselves readable and maintainable.
Cons of v2 vs v1:
- The primary downside of v2 is that an engineer testing their new integration needs to create a fixture generator.
- This is non-trivial, and requires a thorough understanding of the Provider’s EMR and data model.
- However, the effort required to do this is roughly equal to the effort required to set up a v1 integration test.
So, for a similar-sized investment as v1, v2 gives us a major boost in test coverage, along with more readable and maintainable tests.
The v2 test framework has already prevented a number of regressions, and has enabled us to safely refactor major parts of our integration infrastructure.
As I think back on it, this project for me underscores the importance of regularly reviewing tools, frameworks and processes to determine if they’re still the right solution for the problem. The v1 framework served us very well when we had a smaller number of providers and less complex product workflows. But as Cedar grew, we needed to evolve our framework to keep up.
Thanks for reading!
____________
About the Author: To learn more about Jon Collette, check out his LinkedIn profile.
To learn more about Cedar, visit our website.
Interested in a career at Cedar? Check out our careers page.
