In the healthcare and financial industry, data plays a crucial role in enhancing efficiency and elevating patient care. As organizations grow and evolve, their data requirements expand exponentially. Scalability becomes essential to ensure that data infrastructure can accommodate increasing volumes of data, users, and analytical workloads without compromising performance or reliability.
Let's explore our journey of solving scalability challenges using horizontally scalable architecture and centralizing analytics over distributed data systems.
Architectural Evolution: Vertical Scaling to horizontal Scaling
As Cedar's platform grew, so did our challenges, particularly with database scaling. We had one production environment and were limited to vertical scaling. Vertical scaling worked for the early days of the company, but as we onboarded more customers and served more patients every year our engineers realized that we needed a horizontal scaling strategy that would not limit the company’s growth in the long run.
To address this, Cedar made a strategic shift to PoD architecture—a modular design pattern that facilitates horizontal scaling by creating multiple full copies of our production environments, ensuring agility and scalability needed to accommodate a growing portfolio of healthcare providers and patients.
Now, we're running four live instances of our production environment, which has enabled Cedar to provide a stable environment to all of our customers while continuing to grow the business.
Key Features and Benefits of Multi-PoD Architecture
- Agility and Flexibility: One of the standout features of multiple Point of Delivery (Multi-PoD) architecture is its agility and flexibility. With Multi-PoD in place, Cedar gained the ability to rapidly deploy and scale services, allowing us to adapt quickly to changing business needs and market conditions.
- Resilience and Fault Isolation: Each pod operates independently, minimizing the impact of failures or performance issues on the overall system. This fault isolation not only enhances Cedar's system resilience but also ensures continuity of operations, even in the face of localized disruptions.
- Resource Optimization: Resource optimization is another key benefit of Multi-PoD architecture. By distributing workloads across multiple pods, Cedar optimizes resource utilization, improving performance, and enhancing overall efficiency. Whether it's computing power, storage, or network bandwidth, Multi-PoD architecture ensures that Cedar maximizes the use of available resources, minimizing waste and reducing operational costs.
- Customization and Specialization: Perhaps the most exciting aspect of Multi-PoD architecture is its customization and specialization capabilities. Pods can be tailored to specific use cases, workloads, or customer segments, allowing Cedar to deliver personalized solutions that meet the unique needs of our diverse clients.
Unifying Data: How We Centralized Data Across Distributed Data Systems
With Horizontal scaling, the platform expanded across Multi-PoD environments, the introduction of distinct databases within each PoD presented a challenge. This distributed data landscape complicated analytics and data management, prompting the need to centralize its data for analytics. In response, Cedar rolled out a new data infrastructure framework to tackle this challenge.
The initial step of this framework involved the implementation of schemas specific to each PoD. This ensured data remained isolated, performance was optimized, and customization could be tailored to meet the unique requirements of each PoD environment.
Following this, Cedar established a centralized schema to facilitate cross-PoD data access. This centralized schema served as a hub for comprehensive analysis and decision-making across the organization. Importantly, these schemas were designed to expose data from raw sources using views, such that it avoids data duplication and maintains a single source of truth.
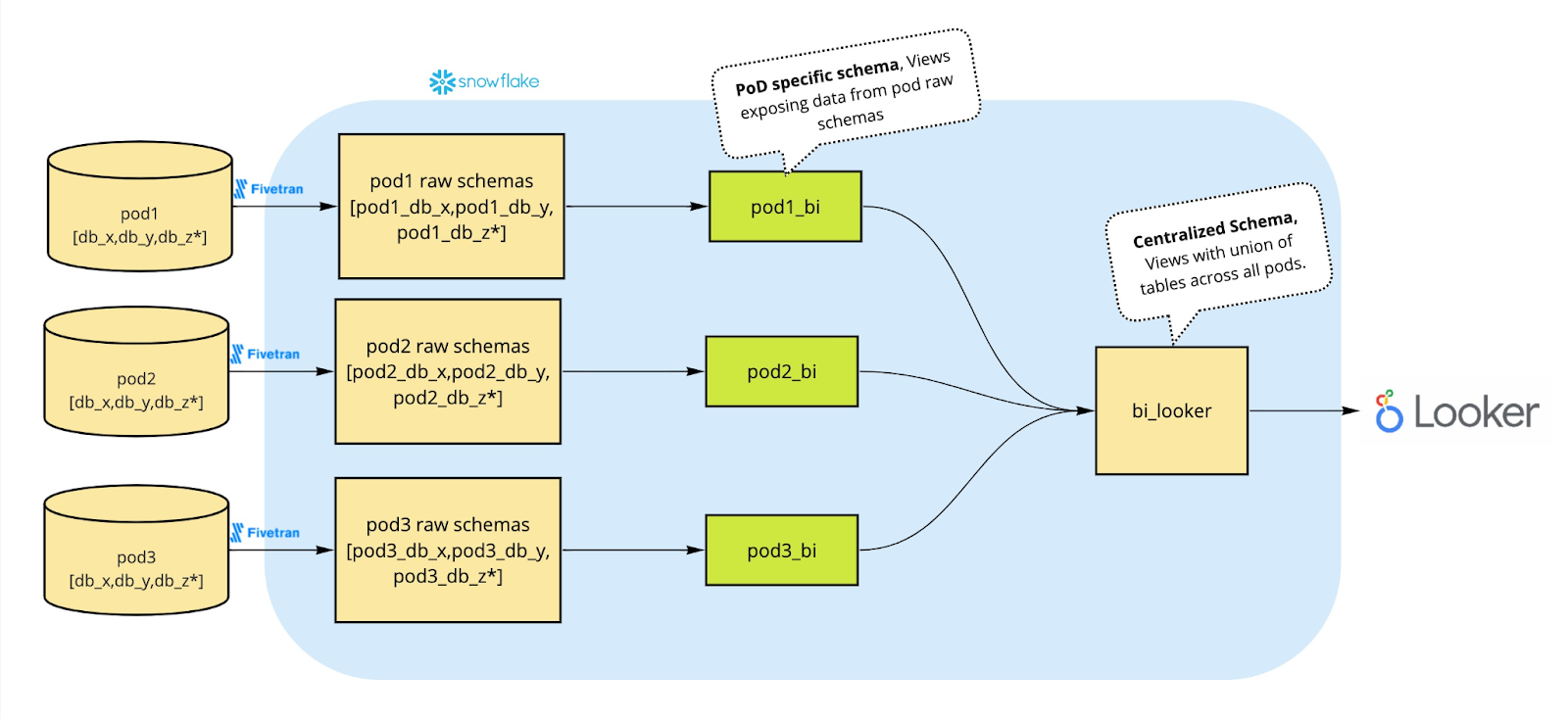
By consolidating data from multiple PoDs into a centralized schema, Cedar gained a unified view of data, which can be easily leveraged for analytics, reporting, and making informed decisions based on comprehensive insights.
However, transitioning to a centralized schema posed challenges, including unique identifier clashes, constant schema updates and schema discrepancies due to varying PoD release schedules.
Here are the approaches we used to overcome these challenges.
Unique Identifier Management:
Before PoDs we could rely on primary keys being unique and we could rely on only one active production schema at any given time. After implementing the PoD architecture, more than one pod can have the same key for a table, so we could no longer guarantee that primary keys would be unique across PoD, this could lead to data integrity issues in our centralized schema. To address this issue, we implemented a solution by defining a pod prefix ID for each PoD and prefixing all identifiers (both primary and foreign keys) with these PoD-prefix IDs. As a result, views in the centralized schema now utilized table metadata to identify the primary and foreign keys columns and used this newly generated ID as the key.
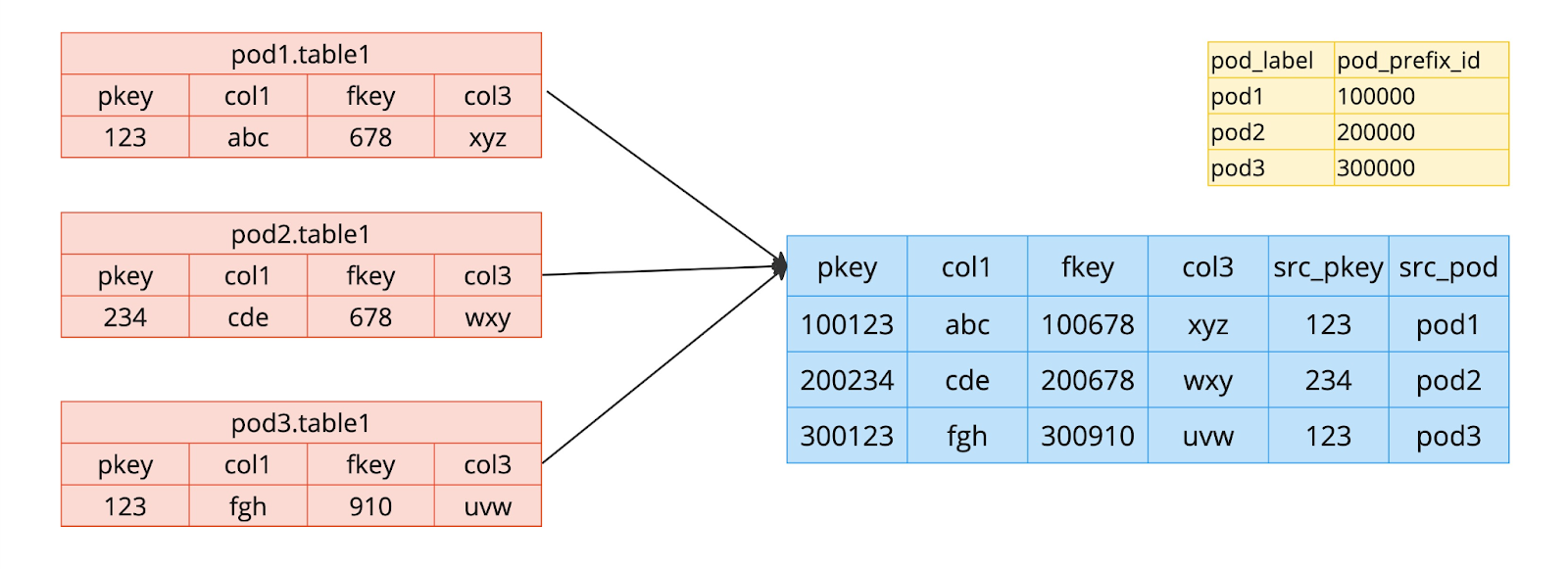
In the example provided, the pkey column in table1 holds the value 123 for both pod1 and pod3, the fkey column has the value 678 for both pod1 and pod2. Adding the pod prefix to the pkey column during a union operation ensures uniqueness and prevents conflicts.
This data unification strategy guaranteed identifier uniqueness across all pods and avoided the need for queries to be rewritten.
Schema Synchronization:
Another challenge stemmed from the constant updates to the production environment and, given that we now have more than one production environment we may roll out updates to one environment asynchronously from others. This can result in discrepancies in the database schema causing tables/columns to be unavailable in snowflake bi schemas. To address this, we established an automated schema synchronization process. This process continuously monitored schema changes across PoDs, generated dynamic view definitions and updated the pod specific and centralized schema to align with the latest definitions. Performing the union for the centralized schema ensured tables and columns were exposed irrespective of whether they were available in all PoDs.

In the given scenario, let's imagine that the release for pod2 hasn't taken place yet, resulting in the absence of col3 in table1 for pod2. However, the schema synchronization process detects the availability of col3 for pod1 and pod3, and proceeds to include it in the centralized schema, with a null value assigned for pod2.
By streamlining schema management, we ensure data consistency and compatibility, enabling smooth analytics operations.
It's essential to acknowledge that schema modifications are inevitable, and adapting to these changes is vital for upholding data integrity and reliability. Organizations can achieve this by tapping into database-provided system tables, metadata management tools, or creating bespoke metadata tracking systems to fetch the latest table definitions directly from the source. This approach ensures that the view definitions generated for the centralized layer remain synchronized with the source, thereby preserving alignment and consistency across the data ecosystem.
Moreover, it's crucial to emphasize the importance of selecting a consistent data type for prefixes to avoid identity conflicts without causing downstream disruptions or performance bottlenecks. Maintaining consistency in data types ensures compatibility and coherence across the entire data environment. While hashing can be effective in generating unique keys, its utilization in views may introduce performance challenges due to the computational overhead associated with hashing extensive datasets. It's imperative to meticulously weigh the trade-offs and explore alternative strategies, such as employing a centralized service for generating unique IDs or leveraging UUIDs (Universally Unique Identifiers) to ensure uniqueness while mitigating performance impacts and achieving the desired functionality.
____________
A special thanks to Pen Jones and Riley Schack for their contributions to this piece.
About the Author: To learn more about Disha Gupta, check out her LinkedIn profile.
To learn more about Cedar, visit our website.
Interested in a career at Cedar? Check out our careers page.