At Cedar, we’ve embraced automated testing since we began building out our product; every change has to pass a suite of tests before it can go into our daily releases. After years of development, we’ve ended up with tens of thousands of automated tests covering all areas of our software. As our test suite has grown, we've had to adjust our testing strategy to keep the test suite running in a reasonable amount of time - slow testing is frustrating for engineers, who can’t move quickly if they’re constantly waiting for a lengthy test suite.
The main change in our strategy was to write more unit tests, which focus on a small area of the codebase, and fewer end-to-end tests, which operate across the backend and make database calls. Early benchmarking showed that unit tests executed up to 20x faster than the end-to-end tests they replaced. However, not all of our unit tests showed such a dramatic improvement.
After digging into this further, we realized that unit tests which held system time to a constant value took significantly longer to run than those that didn't. We were using the very popular Python library FreezeGun in these tests and all signs pointed to it being the cause of the long runtimes. In disbelief, we did some searching online to see if anyone else was experiencing this slowness. We found out that not only were other FreezeGun users experiencing performance issues, but one of those users had written a new library—time-machine—to solve the problem.
FreezeGun, I thought you were my friend!
FreezeGun’s approach to mocking time is to loop through all loaded modules, find imported attributes related to reading system time, and replace them with fakes. As a result, the time it takes to start mocking grows longer as the codebase grows larger. There was no way to know how much of an improvement switching to time-machine would make in our codebase without trying it.
We decided to run a trial in one test case that made heavy use of time mocking. We measured before and after runtimes at two different levels:
- The runtime of the entire test case, which included over 50 usages
- The runtime of entering a single with block.
On a laptop, both measurements showed that using FreezeGun to mock time took over 300 milliseconds longer per usage than using time-machine. With thousands of usages across our test suite, that meant we were spending several minutes just mocking time every time we ran the tests!
The Old Switcheroo
From there, we set about switching libraries, optimistic that it would make a material improvement in the runtime of our test suite. While the API for both libraries is similar, we couldn't perform a purely find-and-replace switch. The largest point of friction was that by default, FreezeGun holds time constant at the specified value, while time-machine sets time to the specified value, but keeps time moving forward. To work around this without changing how our team thinks about mocking time, we wrote our own small wrapper around the time-machine library that uses our preferred default behavior.
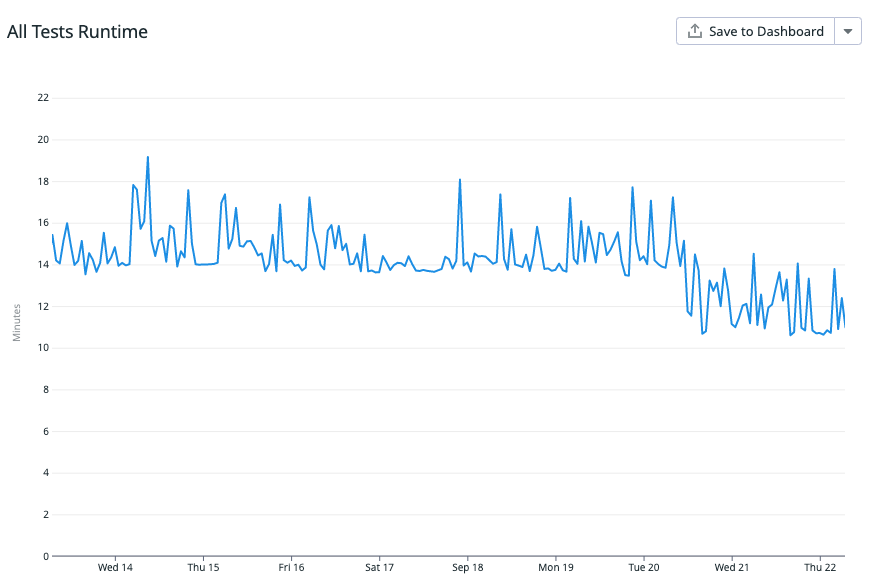
With thousands of usages to replace, we spread the changes over several pull requests, each targeting a different area of the codebase. After each PR was merged, we looked to our metrics to see the impact of the switch. The impact of the largest PR was an improvement of several minutes. This impact is even more impressive considering that we run our test suite in parallel across five workers. The chart below displays test runtime, showcasing the period when the largest PR was merged.
Relentless Improvement
Switching to time-machine from FreezeGun was a good step in our effort to keep test runtime under control. But, it won’t be the last step we take. As our test suite grows with our system, we will need to continue to invest in improvements to our tools and practices. Shipping metrics from our test runners to our metrics system has given us a powerful tool to help guide those investments. It has helped us spot unintended slow downs, and increased “flakiness” in our tests so we can quickly react to preserve a fast, and reliable test suite.
Ethan Young is a Staff Software Engineer at Cedar. To learn more about Ethan, connect with him on LinkedIn.